Most founders will discover this shift six months too late. A recent move by the US government and Anthropic is quietly sorting the AI world into two camps: the ones training on the frontier and the ones always catching up. This is why it matters now, not later.
How Washington wired itself into the labs
The government has been wiring itself into these AI labs since at least mid-2025. Back in July 2025, the Department of Defense handed out contracts worth up to $200 million each to Anthropic, Google, OpenAI, and xAI. These contracts targeted frontier AI for national security. then things got intense. By early 2026, Anthropic drew a line on how its models could be used militarily, and the Pentagon designated Anthropic a supply chain risk, gave the military six months to phase Claude out, and had OpenAI move in to cover classified work.
Eighteen days, off and on
On April 7, 2026, Anthropic (the company behind Claude) released a model, Claude Mythos Preview. Anthropic claimed the model was too dangerous for public release; access went only to a small set of cyberdefenders and critical-infrastructure providers, about 50 at first, expanded by roughly 150 more in early June.
They added more guardrails and safety layers, particularly around biology, cybersecurity, and LLM R&D. This allowed them to release a safer version, Fable 5, to the public on the 9th of June. Anyone with a paid plan has access to it. We tested it on learning and coding tasks; it outperformed the previous models we'd been using. Using the teach skills from Matt Pocock, we created a networking course with a fully laid-out roadmap. Previous models like Opus 4.8 struggled with physics simulations and character skins in game dev; Fable 5 handles both. For example, one user on X built a fully fledged browser-based video game with Fable 5. X
Using Fable 5 felt closer to describing what we wanted in plain English and getting working code back. On June 12, barely three days after the release of the model, we found out by 6 pm that the model had been restricted by order of the US government. What the government acted on, per Anthropic, was a method of bypassing Fable 5's safeguards to surface software vulnerabilities, a flaw flagged by Amazon researchers. Separately, Pliny the Liberator on X claimed a public jailbreak within 48 hours of release, though Anthropic disputes that it was a genuine jailbreak. Such attempts are common in the AI field; models are frequently tested this way.
According to Anthropic, the government never spelled out its specific national security concern. The directive was blunt: no foreign national could touch the model, inside or outside the US, Anthropic's own noncitizen employees included. To stay compliant, they had to pull Fable 5 and Mythos 5 for everyone.
At first, this looked like an Anthropic problem. Then, on June 26, OpenAI previewed GPT-5.6 and, at the government's request, limited it to roughly 20 partners the government itself had to approve. Same playbook, different lab. Anthropic is no longer being singled out; Washington is starting to treat the most capable US models as products that need government sign-off before they ship. OpenAI didn't hide its frustration, saying plainly that this kind of access process shouldn't become the default. The concern, again, was cybersecurity: GPT-5.6's exploit-finding ability is both its headline capability and its headline risk.
Why bar foreign nationals?
But that raises a question: why bar foreign nationals, specifically including the noncitizen researchers inside Anthropic who helped build the model? The US already imposes export controls on hardware firms like Nvidia to suppress one of its biggest competitors, China. So national security may not be the whole story, but the foreign-national detail is the part that never fully adds up.
The US has the top researchers, the biggest labs, and the most funding globally. They dominate the global AI ecosystem: US firms took $285.9 billion of 2025's $344.7 billion in global private AI investment, about 83%, and North America holds the largest regional share of the AI market, around 36% of the global AI market. They understand that whoever masters AI first gains a decisive advantage. Economies, militaries, and research output all shift toward whoever deploys the best model first. That kind of advantage isn't something you share. It's something you protect. When a model gets switched off overnight, then returned to approved institutions first, the question isn't when we'd be let back in. It's that we were never the ones deciding. Frontier access isn't a product being sold to the world; it's a national asset, and its owners can revoke it, ration it, or restore it on a timeline you don't set. If our edge depends on a model another government can switch off, we don't have an edge. We have a lease. The answer isn't to wait for the door to reopen. It's to build on models no one can take back.
From their side, the logic is clear. A country that understands AI's future doesn't hand its best model to the world on day one. They let their own people train with it first. By the time everyone else catches up, you're already ahead, and that advantage compounds.
Now the shift.
These events reveal a pattern: frontier access is scarce, and the gap compounds fast. AI can now do far more than most founders realize. The US government restricts access because it understands how powerful these models are; giving everyone access would shift the balance of power. The response is two moves: change what we build on and start before the gap widens.
Embrace Open-Weight Models
The open-weight movement didn't start with DeepSeek. Mistral and Qwen were already in serious production use. But DeepSeek-R1, released January 20, 2025, broke into the mainstream. The reasoning model went toe-to-toe with OpenAI's o1 on benchmarks at a fraction of the cost, while its sibling DeepSeek-V3 traded blows with GPT-4o and Claude 3.5 Sonnet. A week later, on January 27, 2025, the shock wiped ~$600 billion off Nvidia's market value in a single day, the largest one-day loss in US market history. Teams saw what open weights could do and started shipping them to production.
When a model is open-weight, its parameters are published with little or no restriction: you can download them, run them on your own hardware, fine-tune them, and inspect what's inside. Open-weight isn't the same as fully open-source training. Code and data often stay private, but it hands you the part that matters most for building.
Fast-forward to 2026, and the frontier is competitive on both sides, closed and open. The open-weight side is led largely by Chinese labs; Google (Gemma) and OpenAI (GPT-OSS) have shipped capable open releases too, but the Chinese teams keep setting the pace. The clearest example came on June 13, a day after the US restricted Fable 5 and Mythos 5 from foreign nationals: Chinese company Z.ai released GLM 5.2, a 740B+ parameter mixture-of-experts model (~40B active per token) under a permissive MIT license.
The benchmarks put it head-to-head with the closed frontier. It edged out OpenAI's GPT-5.5 on SWE-bench Pro (62.1 vs. 58.6), took first place on Design Arena ahead of Anthropic's Fable 5, and landed within a few points of Claude Opus 4.8 on agentic coding at roughly one-sixth the API cost. The chart below is Z.ai's official scorecard; other labs have since run their own evaluations and reached similar conclusions. A caveat: some independent evals came in below Z.ai's published figures. Full reproducibility is still being worked out; treat the leaderboards as directional.
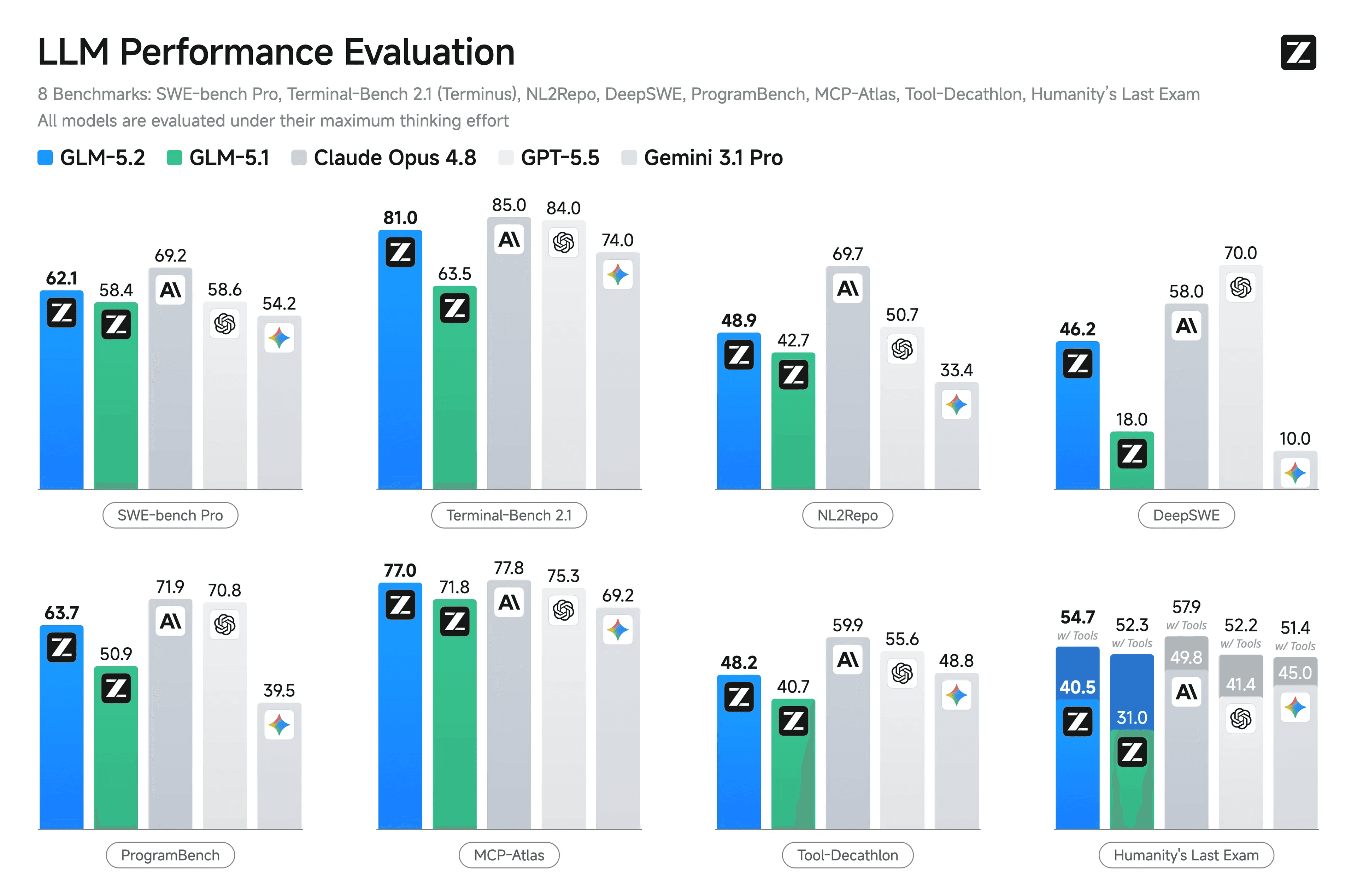
And GLM 5.2 isn't a one-off. Stanford's 2026 AI Index puts the gap between the best US and Chinese models at just 2.7%, down from 17.5-31.6 points in 2023. The frontier still leads, but the lead is now thin enough that an open, self-hostable model is a real production choice, not a compromise.
Top labs keep this flexibility behind paid APIs. Download the weights, host them where you want, and fine-tune them for your workflow, your org, or a daily-driver agent. You get frontier-grade output with no monthly subscription and no vendor that can switch you off. That last part isn't hypothetical: MIT-licensed weights, once downloaded, can't be revoked by any export directive.
The Compounding Effect
And that's exactly how it played out. The block didn't last: Mythos 5 access returned to government-approved organizations first on June 26, and on July 1 the Commerce Department lifted the controls entirely. Fable 5 came back globally, foreign nationals included. Eighteen days, off and on, and no user anywhere had a say either way. That ordering, approved institutions first then everyone else, is the whole point: whoever starts sooner pulls ahead, and the lead compounds.
When six Amazon engineers were told to rebuild the Bedrock inference engine, a project originally scoped at 30 developers over 12 to 18 months, they spent their first weeks not shipping code but redesigning how they worked with AI. Then the results landed: 76 days to delivery, individual productivity up roughly 20x, and more production code in five months than the team had shipped in the previous ten years. The slow start was the investment; the payoff came after.
That curve is why the US is seeding its own institutions first: a head start now is hard to catch later. But here's what the gatekeepers can't touch: you don't have to care whether the gate is open or shut. The open-weight models we looked at sit at nearly the same frontier, and no one can switch them off. As builders, we shouldn't wait to regain access to models we were never guaranteed in the first place. If your hardware can run them, pull the weights from Hugging Face, fine-tune them to your workflow, and host them for your team or your agents. You own that stack. No directive revokes it, no plan reinstates it on someone else's schedule, no one decides whether we're allowed in.
And notice how it came back: not clean, but metered. For the first week, Fable 5 is capped at 50% of your plan's usage limit, and then it moves to paid usage credits. Its safeguards returned broad: a routine request tripped Fable 5's filter and silently dropped us to Opus 4.8. Anthropic's own notice admits the guards "may flag safe and routine coding, cybersecurity, or biology work."
Stack it up. First, the government decides whether you're allowed in. Then the vendor decides how much you get. Then a safety classifier decides, request by request, which model you actually reach. At no layer is the access yours. That's the lease, and that's what renting the frontier feels like on a good day.
Open-weight models are here to stay, and they're closing the gap with every release. The best open models now trail the closed frontier by low single digits, down from double digits two years ago. The teams that win won't be the ones that let a government directive freeze their product roadmap.